|
“眼见为实”。
在餐桌上,有些并非从事科学研究的人常常问我目前正在研究什么,当我回答说,我正在思考哺乳动物视觉系统的某些问题即我们如何看东西时,他们往往会表现出令人有些窘迫的沉默。提问者往往迷惑不解,为什么像看东西这么简单的事情还会有困难。当我们睁开眼睛时,毕竟不费吹灰之力就可以看到一个开阔清晰、充满五颜六色物体的世界。一切都显得轻松自如,因此还有什么问题可言呢?当然,如果我现在潜心钻研的是数学、化学甚至经济学这些需要花费脑力的问题,也许还有值得谈论的东西。然而,看……?
另外,很多人认为,既然他们的大脑工作得很好,于嘛还要自寻麻烦呢?他们认为,与脑有关的主要问题是当它出了毛病的时候我们如何去治疗。只有少数有科学头脑的人才会进一步追问:当我们看某个物体时,大脑究竟是如何工作的呢?
我们现有的视觉系统知识,有两方面是相当令人吃惊的,第一方面,我们已经具备的知识量,无论用什么标准衡量都是庞大的,学校设有齐全的视觉心理学(如:在什么条件下电影屏幕上快速连续呈现的静止图像能够产生平滑的运动)、视觉生理学(眼睛及相关脑区的结构和行为)和视觉分子及细胞生物学(神经细胞及其组成分子)课程。这些知识是众多从事人类和动物研究的实验家和理论家经过多年艰辛努力积累的结果。
另一个惊人之处是,尽管已经有了这些工作,但对如何看东西我们确实还没有清楚的想法。对那些进修这些课程的学生,往往隐瞒了这一事实。当然,如果经过所有这些认真的研究和详尽的讨论之后,我们对视觉过程仍然缺乏清晰、科学的了解,那可能就是不应该的了。按照严格的科学(如:物理学、化学、分子生物学)标准,我们对于大脑如何产生生动的视觉意识甚至还缺少大体的了解,我们只是把它看成是理所当然的事情。我们知道该过程的某些零散的片段,但我们还缺乏详尽的资料和想法来回答某些最简单的问题:我们怎样看颜色?当我回忆一张熟悉面孔的图像时,发生了什么事情?等等。
但是还有第三件令人奇怪的事情。你可能对自己如何看东西已经有了一个粗略的想法。你认为,每只眼睛就像一部微型电视摄像机,利用角膜透镜把外界景象聚焦到眼后一个特殊的视网膜屏幕上。每个视网膜有数以百万计的“光感受器”,对进人眼睛的光子进行响应。然后,你把由双眼进入大脑的图像整合到一起,这样,就可以看东西了。在没有考虑这些问题之前,你也许对可能的发生过程有了某些想法。但是,也许让你惊讶的是,即使科学家还不知道我们怎样看东西,但却容易说明,你把如何看东西想得太简单了,在很多情况下或者说是完全错了。
我们多数人想像的图景是,在我们大脑的某处有一个小矮人,他试图模仿大脑正在进行的活动,我们将其称为“小矮人谬误”(the
Fallacy of the Homunculus。在拉丁文中homunculus的意思是小矮人)。很多人确实有这种感觉(在一定的时候,这个事实本身就需要解释)。但我们的“惊人的假说”并不认为是如此。粗略他说,它认为“所有这些都是神经元完成的。”
有了这一假设,看的问题就赋予了全新的特性。简而言之、大脑中必定存在某些结构或操作,它们的行为就好像以某种神秘的方式与“小矮人”的精神图像相对应。但它们会是些什么东西呢?为了研究这一难题,我们必须了解看所涉及的任务及头脑内完成该任务的生物装置。
你为什么需要视觉系统呢?一种巧妙的回答就是它能使你或帮助你的亲属繁衍后代。但这一回答太笼统了,我们从这里得不到多少东西。实际上,动物需要利用视觉系统去寻觅食物、躲避天敌和其他危险,交配、抚养后代(对某些物种)等等也离不开视觉系统。因此一个良好的视觉系统是无价之宝。
加利福尼亚州理工学院的神经生物学家约翰・奥尔曼(JohnAllman)认为,与爬行类相比,哺乳动物由于它们不停的活动和相对高而恒定的体温,因此就需要保存更多的热量。对于小的哺乳动物而言尤其如此,因为与体积相比,它们的表面积太大了,因而就有了软毛(这是哺乳类独一无二的属性)和高度发育的新皮层。他相信,这一脑区的发育使早期的哺乳动物更聪明,它们可以找到充足的食物用以保持体温。
尽管哺乳动物智力比较发达,但作为一类动物它们并没有特别的视觉系统。这可能是因为它们是从小型夜行动物进化而来的,而这些动物的视觉远不及嗅觉和听觉那么重要。而灵长类(猴、猿和人)则是例外。它们大多数具有高度进化的视觉,但和人类相似,其嗅觉也许是较差的。
恐龙灭绝以后,这些早期的哺乳动物很快发展起来,并取代了恐龙留下的生态真空。哺乳动物较为聪明的大脑帮助它们有效地完成这些任务,并最后导致在所有的哺乳动物中最为聪明的人类的突现。
哺乳动物的眼睛有什么用途呢?进入我们眼内的光子仅能告诉我们视野①中某个部分的亮度和某些波长信息,但是你想要知道的是那里有什么东西,它正在做什么和可能去做什么。换句话说,你需要看物体、物体的运动和它们的“含义”。即它们通常做什么,有何用处,在过去你在何种环境中见过它们或类似的东西等。
为了生存和繁衍后代,你需要的并不仅仅是这些信息。用计算机的术语来说,你必须做到“实时”,即在这些信息过时之前,足够迅速地采取行动。如果计算明天的天气预报要花费一周的时间,就算高度准确这也是没有多大意义的。所以,尽快地提取生动的信息是再重要不过的了。当动物试图捕杀其他动物时,无论对于捕食者或被捕食者,这都是特别重要的。
因此,眼和大脑必须分析进入眼睛的光信息,以便获得所有这些重要的信息。它怎样完成这一任务呢?在更详细地描述看所涉及的东西之前,首先让我给出如下三条基本的评论。
1.你很容易被你的视觉系统所欺骗。
2.我们眼睛提供的视觉信息可能是模棱两可的。
3.看是一个建构过程。
尽管三者并不相关,我们还是依次叙述。
你很容易被你的视觉系统所欺骗。比如,许多人相信,他们可以同样清楚地看任何东西。正如同我通过窗户观察花园时,我的印象是面前的灌木和右方的树木一样清楚,如果我的眼睛在短时间保持不动,就很容易发现这种感觉是错误的。只有接近注视中心,我才能看到物体的细节,偏离注视中心视力就越来越模糊,而到了视野的最外围,我连辨别物体都有困难,在日常生活中,这一限制之所以显得不明显,就是由于我们很容易不断地移动眼睛,使我们产生了各处物体同样清晰的错觉。
拿起一个有颜色的物体,比如蓝色的笔或红色的扑克牌,井把它放在头的侧后完全不能看见的地方。然后,慢慢向前移动它,使它刚好进入视野的边缘,注意,你的眼睛千万不能动!这时,如果你晃动该物体,在你看清楚它是什么之前,就已经感到那里有东西在动。在你能确定那笔是什么颜色之前,你能区别它是水平的还是垂直的。一直到你把它移到非常接近注视中心之前,即便你可以看见它的形状和颜色,但仍不能看清物体的细节。我的笔上有一个“extra
fine point”标志。它印得非常小,但我戴上眼镜并把它放在一英尺处,就可以很清楚地读出它。但是,如果将手指放在笔的旁边,且注视点不是在笔上而是在指尖处,我就读不出笔上写些什么东西,尽管它们离注视中心已经很近。我的视锐度随着离开注视中心的距离而迅速下降。
为了用简单和直接的方法演示视觉系统如何欺骗我们,让我们看一下图1,这时,你立刻就会看到一条由背景包围的水平纹理条带。背景的左侧是黑色,然后从左向右逐渐变白,水平条带本身,左侧看起来明显地比右侧亮,但事实上,在整个水平条带的宽度范围,其纹理的亮度都是均匀的。如果你用手挡住背景,你会很容易看到这一点。
我们的视觉系统还可以以更加巧妙的方式欺骗我们。图2是著名的卡尼莎(Kanizsa)三角,因工作于的里雅斯特(Trieste)的意大利心理学家盖塔诺・卡尼莎(Gaetano
Kanizsa)而得名。你将会看到一个大的白色正三角形呈现在三个黑色圆盘①之前。而且这一白色三角形也许显得比图形的其余部分更亮一些。

这种错觉白色三角形的轮廓常被称为“错觉轮廓”,因为那里并不存在真实的轮廓线。当你用手挡住图形的大部分而只露出很短一段“轮廓”时,你就会发现,原来具有可见轮廓的纸面现在看来是均匀的亮度,没有任何轮廓。
我的第二个一般评论是,我们眼睛提供给我们的任何一种视觉信息通常都是模棱两可的。它本身提供的信息不足以使我们对现实世界中的物体给出一个确定的解释。事实上,经常会有多种可信的不同解释。
一个明显的例子就是在三维空间看物体。如果你将头固定不动并闭上一只眼睛,你仍然可以得到某种程度的深度知觉。这时仅有的视觉信息来自你睁开的那只眼睛的视网膜上的二维图像。假如你的正前方的物体是位于一定距离、具有均匀白色背景的正方形框架(如图3a),你当然会把
它看成是一个正方形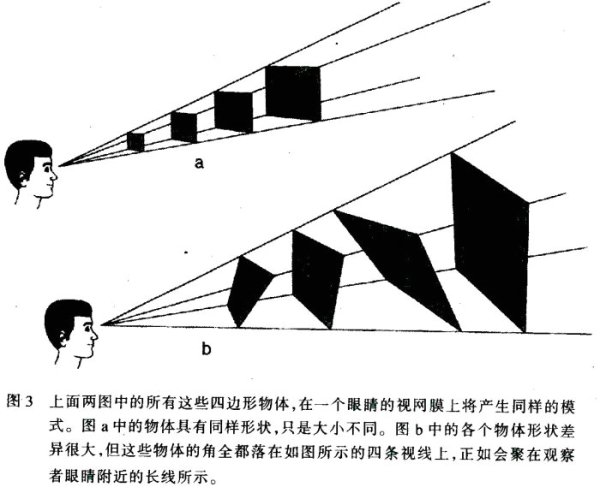
然而,这个线框图形也许实际上根本不是正方形,而是由一个倾斜的、具有某个特殊形状的四边形产生的(如图3b),而它在视网膜上的像刚好与正对着你的正方形完全相同。此外,还会有大量扭曲的其他线框图形可以形成相同的视网膜图像。
这个例子也许显得有些太特殊,因为一个人很少会闭上一只眼睛又固定头部来观察世界。假如你观察一幅照片或某个景物的写生画,此时,即使你转动头部和使用双眼,也只能看到一张平面的照片或图画。但在多数情况下,你仍可以看到图画中表达的三维信息。
某些简单的线画图形可能有几种同样可能的解释。请看图4。该图由画在纸的表面上的十二条连续的黑直线组成。但几乎每个人都会将其看成是三维立方体轮廓图。
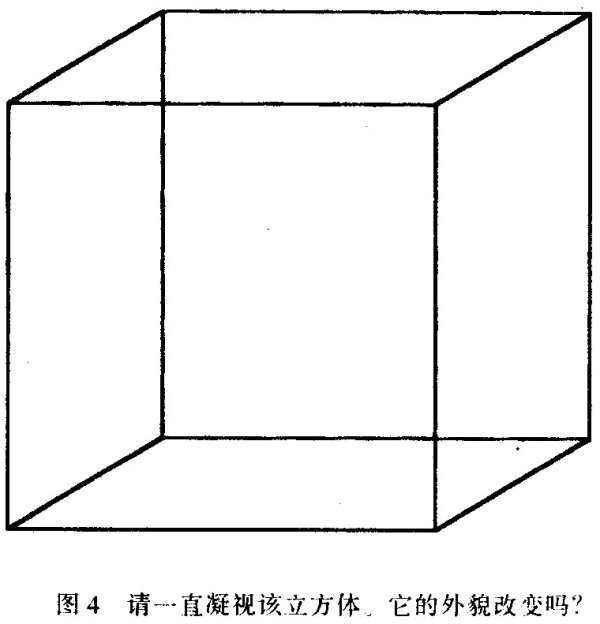
这个被称为内克(Necker)立方体的特殊图形有一个有趣的性质。如果较稳定地注视一会儿该图形,立方体就会发生翻转,仿佛观察角度发生了变化一样。再过一会,知觉又会转换到原来的那样。在这种情况下,这幅图像有两种同样可能的三维解释,大脑无法确定哪一个更可取。但值得注意的是,某一时刻只能有一种解释,并不是二者奇特的混合。
对视觉图像的不同解释是数学上称为“不适定问题”的例证。对任何一个不适定问题都有多种可能的解。在不附加任何信息的条件下,它们同样都是合理的。为了得到真实的解,即与那里真正的东西最接近的解(有时用其他检验去测量,如走过去摸一摸它),我们需要使用数学上的所谓“约束条件”。换句话说,视觉系统必须得到如何最好地解释输入信息的固有假设。
我们通常看东西时之所以并不存在不确定性,是由于大脑把由视觉景象的形状、颜色、运动等许多显著的特征所提供的信息组合在一起,并对所有这些不同视觉线索综合考虑后提出了最为合理的解释。
我的第三个一般性评论认为,看是一个建构过程,即大脑并非是被动地记录进入眼睛的视觉信息,正如上面的例子所显示的那样,大脑主动地寻求对这些信息的解释。另一个突出的例子是“填充”过程。一种类型的填充现象与盲点有关,它的发生是由于联结眼和脑的视神经纤维需要从某点离开眼睛,因此,在视网膜的一个小区域内便没有光感受器。请你闭上或遮住一只眼睛并凝视正前方。垂直地举起一个手指,把它放在距鼻尖约一英尺处,使指尖和眼睛的中心差不多处于同一水平,在水平方向移动手指使它偏离凝视中心约15度。稍加搜索你就便会发现一个看不见你指尖的地方(一定凝视正前方)。你视野内的这一个小区域是盲区。
尽管这里存在盲区,但在你的视野中似乎没有明显的洞。比如我前面讲过的,当我在家中从窗户看外面的草坪时,即使我闭上一只眼睛观看正前方,我也感觉不到在草坪中有洞。也许看起来令人吃惊的是,大脑试图用准确的推测填补上盲点处应该有的东西。大脑究竟如何作出这种推测,正是心理学家和神经科学家试图找到的东西,(我将在第四章较全面地讨论填充过程。)
本章开头我给出了一个短语“眼见为实”。按通常的说法它的意思是,如果你看到某件东西,你就应当相信它确实存在,我将为这一神秘的成语提出一个完全不同的解释:你看见的东西并不一定真正存在,而是你的大脑认为它存在。在很多情况下,它确实与视觉世界的特性相符合。但在某些情况下,盲目的“相信”可能导致错误。看是一个主动的建构过程。你的大脑可根据先前的经验和眼睛提供的有限而又模糊的信息作出最好的解释。进化可以确保大脑在通常的情况下非常成功地完成这类任务,但情况并非总是如此,心理学家之所以热衷于研究视错觉,就是因为视觉系统的部分功能缺陷恰恰能为揭示该系统的组织方式提供某些有用线索。
那么我们应当怎样看待视觉(vision)呢?让我们把那些并不重视视觉问题的人的朴素的观点作为出发点)很清楚,我的头脑中似乎有一幅面前世界的“图像”。但很少有人相信,在大脑的某处有一个真正的屏幕,它产生与外部世界相对应的光模式。我们都知道,电视机之类的装置能够完成这种工作。然而,在打开的头颅中,我们并没有发现按规则阵列排列的脑细胞,它们在发射各种颜色的光。当然,电视图像信息并不仅仅表现在其屏幕上。如果你使用一个特殊的计算机程序来迸行艺术创作就会发现,形成画面所需信息并不是以光的模式存储的。相反,它是以记忆芯片中电荷的序列储存在计算机的记忆中,它可能是以规则的数子阵列形式存储在那里,每个数字代表该点的光强。这种记忆看来并不像图形,然而,计算机可以利用它产生屏幕上的图像。
在此我们举一个符号例子:计算机存储的信息并非图像,而是图像的符号化表示。一个符号就像一个单词,是以一个东西代表另一个东西。狗这个词代表一种动物,但没有人会把这一单词本身看成是真正的动物。符号并不一定是词,例如红色交通信号灯代表“停车”。很清楚,我们期望在大脑中发现的正是视觉景象的某种符号化表象。
那么,你也许会问,我们大脑中为什么没有一个符号化屏幕呢?假使屏幕由一个有序排列的神经细胞阵列组成,每个细胞对图像中的特定“点”进行操作,其活动强度与该点光强成正比。若该点很亮,则该细胞活动剧烈,如果无光,则细胞停止活动。(每点有三个细胞的组合,就还可同时处理颜色。)这样,表象就会是符号化的,假想的屏幕上的细胞产生的并不是光,而是代表光的符号的某种电活动。难道这不就是我们想要的一切吗?
这种排列的毛病是除了每个小光斑之外不能“知觉”任何物体。它能看到的一点也不比你的电视机能看到的东西多。你能够对你的朋友说:“当那个和蔼的女郎开始读新闻的时候,请你告诉我。”但是,试图让你的电视机做到这一点是徒劳的。我们无法使设计的电视机去识别一位妇女,更不用说去识别一位正在做某种动作的特别妇女了。但是,你的大脑(或你的朋友的大脑)却可不费吹灰之力地做到这一点。
因此大脑不可能只是一群仅仅表示在什么地方具有什么光强类别的细胞集合。它必须产生一个较高层次上的符号描述,大概是一系列较高层次上的符号描述。正如我们所看到的那样,这不是一步到位的事情,因为它必须借助以往的经验找到视觉信号的最佳解释。因此,大脑需要建构的是外界视觉景象的多水平解释,通常按物体、事件及其含义进行解释,由于一个物体(比如面孔)通常是由各个部分(如眼、鼻、嘴等)组成的,而这些部分又是由其各个子部分组成,所以符号解释很可能发生在若干个层次上。
当然,这些较高层次的解释已经隐含(implicit)在视网膜上的光模式之中。但仅仅如此是不够的,大脑还必须使这些解释更明晰(explicit)。一个物体的明晰表象是符号化的,无需进一步深入加工。隐含的表象已包含这些信息,但必须进行深入的加工使其明晰化。当屏幕上某处出现一个红点时,要使电视给出某种信号是一件很容易的事情,只要在电视机上加一个小装置就行了,但是,如果想要设计一种电视机,使它当看到屏幕上的任何地方出现女人面孔时就给出闪光,则需要更复杂的信息加工。这实在是太难了,以至于我们今天还不能制造出完成这种任务的复杂装置。
一旦某个事物以明晰的形式符号化以后,该信息就很容易成为通用的信息。它既可以用于进一步加工,又可以用于某个动作。用神经术语来说,“明晰”大概就是指神经细胞的发放必须能较为直接地表征这种信息。因此,要“看”景物,我们就需要它的明晰的、多层次的符号化①解释,这似乎是合理的。
对很多人而言,说我们看到的只是世界的一种符号化解释是难以接受的。因为所有的一切似乎都是“真实的东西”,其实,我们并不具备周围世界各种物体的直接知识。这只不过是高效率的视觉系统所产生的幻觉而已,因为正如我们已经看到的,我们的解释偶尔也会出错。然而,人们宁愿相信存在一个脱离肉体的灵魂,它借助大脑这一精巧的装置,并以某种神秘的方式产生实际的视觉。这些人被称为“二元论者”(dualists),他们认为,物质是一回事,而精神是完全不同的另一回事。与此相反,我们的惊人假说却认为,情况并非如此。所有这些都是神经细胞完成的。我们正在考虑的,是如何通过实验在两者之间作出决断。
①更加准确的术语应该是刺激野(stimulus
field)。但对大多数读者来说,我认为视野(Visual
field)、视场(field Of vision)、视景(visual scene)会更合适。当然,重要的是分清外部世界的物体和看这些物体时你头脑中的相应过程。
①图中单个黑色区域的实际形状――缺口圆盘,通常被称为“派克曼(Pacmen)”。
①使用符号一词并非意味真正存在小矮人(homunculus)。它仅仅表明,神经元的发放与视觉世界的某些方面密切相关,这种符号是否应考虑为一个矢量(而不仅仅是标量)是一个棘手的问题,在此我将不予考虑。换句话说,单个符号是如何分布的? |